
대규모 언어모델 1등 자랑 & 트렌드 공유
페이지 정보
본문
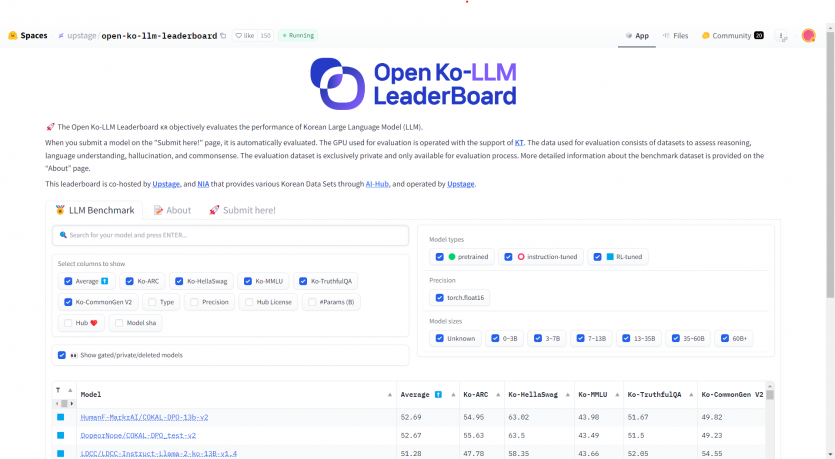
ChatGPT에 대항하기 위해 한국 대부분의 IT 대중소기업들도 거대 언어모델(LLM)을 만들거나 튜닝하는데 뛰어들었고, 추석즈음부터 아예 한국어용 LLM 리더보드가 생겨 공개적으로 점수를 평가받고 있어요.
이번에 제가 이끄는 작은 연구팀이 거기서 1위를 해서 기쁜 마음과 배운점을 클량 식구들과 나누고자 글을 씁니다.
저희가 세운 전략은 크게 '양 보다는 질적으로 좋은 데이터셋', '특정 테크닉 최적화 보다는 다양한 조합 시도' 였습니다.
LLM 분야 연구는 아직 장님 코끼리 만지는 느낌입니다. OpenAI가 노하우를 좀 논문으로 써주면 좋겠는데, 요새는 꽁꽁 숨기고 있거든요. 다른 논문에서 좋다는 테크닉을 쓰거나 좋다는 데이터셋을 한국어화 해서 튜닝을 했는데 더 나이지기는 커녕 후퇴하는 경우도 많아요. 그러다보니 직접 한땀한땀 튜닝하면서 축적되는 노하우와 손맛이 아직 유효한 것 같습니다.
연구도 하고 교류를 하면서 느낀 LLM 트렌드를 몇가지를 공유하면,
대부분의 한국 기업들은 해외 언어 위주로 사전 훈련된 13B와 7B 정도의 작은 사이즈 오픈소스 모델을 가져다가 자체 데이터셋에 파라미터 효율적으로 파인튜닝을 해서 씁니다. 튜닝된 모델은 의외로 한글도 응답을 그럴 듯 하게 합니다. 물론 아직 ChatGPT보다 떨어지는 느낌이 좀 있어요. GPT-4보다는 한참 모질라고요. 그래도 많이 따라왔습니다. 영어 쪽은 크기가 큰 오픈소스 70B 모델로 이미 ChatGPT를 능가한 케이스들도 많이 나왔습니다(그 중엔 한국 회사들도 꽤 있습니다).
LLM 파인튜닝은 GPU 자원을 조금만 투자해도 되기에, 이제 기업들은 private gpt를 가질 수 있습니다. 보안이 보장이 안되기에 기업들은 그동안 함부로 ChatGPT를 못 썼지요. 사전 훈련 모델을 만들려면 A100 GPU 수백개가 사용되기에 얼마전까진 모든 기업은 입맛만 다시는 상황이었어요. 그러다 최근 Llama, Polyglot, Mistral 등 훌륭한 오픈소스 사전 훈련 모델이 공개되었고, 기업들은 이제 자체 데이터로 튜닝만 하면 되기에 접근성이 굉장히 좋아졌습니다.
대부분의 LLM 기업들은 RAG(검색 기반 생성)에 집중하고 있습니다. 환각 증세를 없애고 근거 문서를 기반으로 답하게 만들기 위해 RAG가 고안되었고, 새로운 데이터로 매번 훈련시키지 않고도 신규 정보를 반영하는데에 매우 좋은 시스템이라 그렇습니다. 근데 RAG는 아직 연구가 적어서 성능의 우위를 정량적으로 증명하지 못하더군요. 게다가 RAG에는 쿼리 생성, 문서 벡터화, 벡터DB, 기존 검색엔진과의 앙상블, 결과의 리랭킹, TOP K 선택, 답변 생성 등에서 여러 곳에서 LLM이 사용이 되기에 복합적인 문제이기도 합니다. 단순히 LLM 답변 성능만 뛰어나다고 잘 되는게 아니라 사용성과 견고성 연구도 많이 필요하더군요. 아직 한국어는 ChatGPT만큼 견고하다고 느껴지지 않아서 저희 팀은 보안에 이슈가 없는 경우 ChatGPT로, 보안이 필요한 영역은 자체 LLM을 튜닝해서 RAG를 구성하고 있습니다. 발전이 많이 필요한 영역이라 저희는 RAG 프레임워크를 대부분 오픈소스로 연구자들과 공유하고 있어요.
ChatGPT가 인류에 충격을 준 지 1년도 안되서 한국이 이만큼 따라온 것도 대단하다고 느낍니다. 누군가는 핵폭발 만큼 인류에 영향을 줄 기술이라던데, 그만큼은 모르겠지만 엄청난 잠재성을 지니고 있으니 누군가가 독점하는건 좀 막았으면 좋겠습니다. 곳곳에서 오픈소스 LLM 연구하시는 분들 힘 내시길 바랍니다. 혹시 궁금한게 있으시면 댓글이나 쪽지 주시면 답 드릴게요. 감사합니다.
관련자료
-
이광진 12.31
안귀령님의 말솜씨가 예뿐 언굴과 같아 보기와 듣기가 좋았습니다. 엣말에 …
-
돌아이냐 12.30
머저리야! 죄명이는 2003년 7월 무고 공무원자격(검사)사칭과 관련 벌…
-
작가 이름 수… 12.16
권은지 x 권윤지 ㅇ
-
인마핱 12.16
비밀댓글입니다.
-
민주 11.29
실제 카카오톡 화면이 말하는사람이랑 듣는사람이랑 다 같은쪽에서 나와요? …
-
Www 11.17
아조씨 그건 아저씨가 남자니까 결혼이 좋은 거지
-
멋져부러 11.09
멋져부러 !!!!!!
-
Ww 11.04
임산부 앞에 두고 이기적인 놈
-
매너가 남자를… 10.25
와 너무 멋진 매너 할아버지
-
이원아웃 10.20
제발 이원욱 좀 아웃시켜라!!!! #진석범 검색해보니 괜찮은 사람이더라.…
- 이광진 12.31 안귀령님의 말솜씨가 예뿐 언굴과 같아 보기와 듣기가 좋았습니다. 엣말에 …
- 돌아이냐 12.30 머저리야! 죄명이는 2003년 7월 무고 공무원자격(검사)사칭과 관련 벌…
- 작가 이름 수… 12.16 권은지 x 권윤지 ㅇ
- 인마핱 12.16 비밀댓글입니다.
- 민주 11.29 실제 카카오톡 화면이 말하는사람이랑 듣는사람이랑 다 같은쪽에서 나와요? …
- Www 11.17 아조씨 그건 아저씨가 남자니까 결혼이 좋은 거지
- 멋져부러 11.09 멋져부러 !!!!!!
- Ww 11.04 임산부 앞에 두고 이기적인 놈
- 매너가 남자를… 10.25 와 너무 멋진 매너 할아버지
- 이원아웃 10.20 제발 이원욱 좀 아웃시켜라!!!! #진석범 검색해보니 괜찮은 사람이더라.…