
수능 국어 상위 5% 인공지능으로 달성했어요
페이지 정보
본문
안녕하세요.
제가 오픈소스 거대 언어 모델(LLM) 프로젝트팀을 지도하고 있는데,
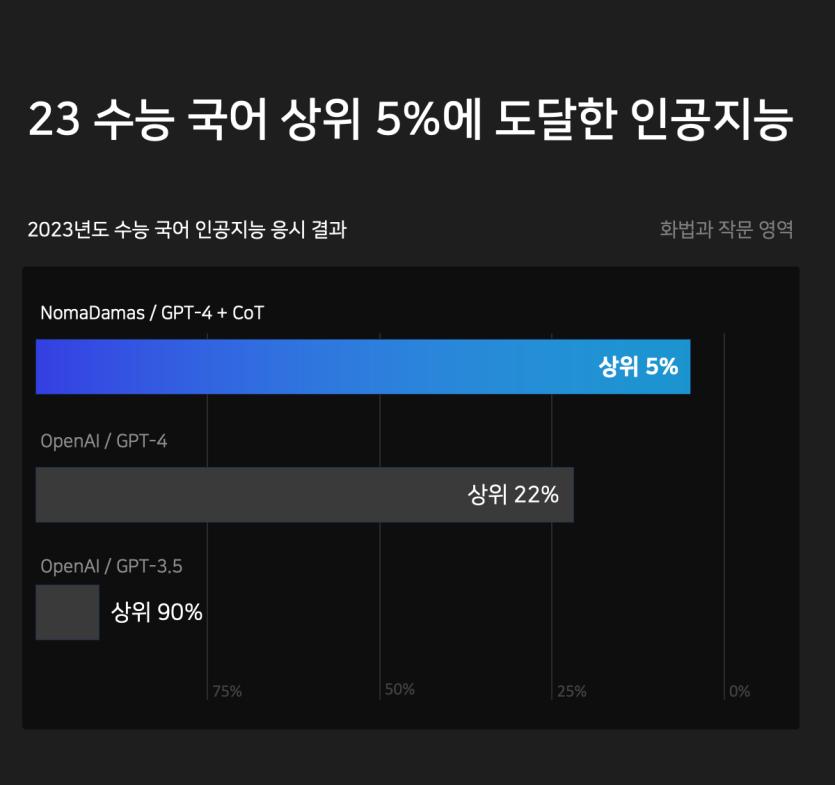
23년 입시 수능 국어에서 상위 5%를 인공지능으로 달성하는 바람에 뉴스 기사가 나와서 클량 식구에게 공유합니다.
방법은 GPT-4에 CoT(생각의 사슬, Chain-of-Thought) 방식의 프롬프트 엔지니어링을 적용한 것입니다.
우리가 실제 시험을 치를 때처럼 각 선택지가 정답이어야 하는 근거를 본문에서 찾게끔 하고 그것을 기반으로 가장 논리적인 정답을 선택하는 방식으로 사고의 흐름을 프롬프트로 개발하여 적용했습니다.
그동안 수능 국어에서 높은 성적을 받은 언어 모델들이 없었기에 영어에 비해서 언어 모델들의 한국어 논리력은 아직 많이 멀었다라고 불과 한달 전까지 강연을 하고 다녔는데, 이제는 바꿔야할 것 같습니다.
솔직히 저도 다시 수능치면 그보다 잘할 자신 없네요.
현재의 인공지능 만으로도 한국어 논리력은 이미 한국 사람의 최상위 수준에 도달한 것이었네요. 그동안 질문하는 방법을 몰랐을 뿐.
근데, 그 인공지능이 하필 미국 꺼에다가 독점적 기업의 소유라서 좀 아쉽네요.
LLM은 이제 단순히 그럴듯한 텍스트를 생성하는 기계가 아니라 논리성을 가진 일반 지능에 가까워서.. 핵폭탄만큼 위협적인 무기가 될 수도 있습니다.
특정 국가나 기업에 독점 권력을 주지 않으려면 한국어 오픈소스 LLM도 빨리 발전해야하는데, 이게 돈이 너무 많이 들어가다보니 참 어렵네요.
그래도 저희 팀처럼 Polyglot이나 LLaMA2 모델로 한국어 오픈소스 열심히 발전시키고 계신 분들도 많이 있습니다. 한번씩 응원 부탁드려요~!
뉴스 링크 : https://www.aitimes.com/news/articleView.html?idxno=152929
관련자료
-
ㅇㅇ 01.08
마포갑은 김빈!! 응원합니다
-
이광진 12.31
안귀령님의 말솜씨가 예뿐 언굴과 같아 보기와 듣기가 좋았습니다. 엣말에 …
-
돌아이냐 12.30
머저리야! 죄명이는 2003년 7월 무고 공무원자격(검사)사칭과 관련 벌…
-
작가 이름 수… 12.16
권은지 x 권윤지 ㅇ
-
인마핱 12.16
비밀댓글입니다.
-
민주 11.29
실제 카카오톡 화면이 말하는사람이랑 듣는사람이랑 다 같은쪽에서 나와요? …
-
Www 11.17
아조씨 그건 아저씨가 남자니까 결혼이 좋은 거지
-
멋져부러 11.09
멋져부러 !!!!!!
-
Ww 11.04
임산부 앞에 두고 이기적인 놈
-
매너가 남자를… 10.25
와 너무 멋진 매너 할아버지
- ㅇㅇ 01.08 마포갑은 김빈!! 응원합니다
- 이광진 12.31 안귀령님의 말솜씨가 예뿐 언굴과 같아 보기와 듣기가 좋았습니다. 엣말에 …
- 돌아이냐 12.30 머저리야! 죄명이는 2003년 7월 무고 공무원자격(검사)사칭과 관련 벌…
- 작가 이름 수… 12.16 권은지 x 권윤지 ㅇ
- 인마핱 12.16 비밀댓글입니다.
- 민주 11.29 실제 카카오톡 화면이 말하는사람이랑 듣는사람이랑 다 같은쪽에서 나와요? …
- Www 11.17 아조씨 그건 아저씨가 남자니까 결혼이 좋은 거지
- 멋져부러 11.09 멋져부러 !!!!!!
- Ww 11.04 임산부 앞에 두고 이기적인 놈
- 매너가 남자를… 10.25 와 너무 멋진 매너 할아버지